Als ein Kollege mir im Büro Gesellschaft geleistet hat, als alle anderen aus diversen Gründen nicht dort waren, hat er beim Confluence aufräumen eine Frage gestellt die mich gleich etwas hellhörig gemacht hat:
Was machen wir eigentlich mit den ERDs?
Und ja, was machen wir damit? Zum einen sind die vermutlich nicht gepflegt, weil Doku macht meistens nur eins: altern
und zum anderen falsch sein. Weil niemand sie aktiv pflegt.
Google hat vor circa drei Wochen das Open Knowledge Format (Stand 02.07.2026) vorgestellt und das kam mir bei dem Thema gerade in den Kopf.
Was ist wenn wir unser ERD als Markdown vor halten?
Und genau da kam mir die Idee das ganze einmal auszuprobieren.
Die Vorteile lagen für mich irgendwie auf der Hand, da wir sowieso viel mit LLM Programmieren.
Die verstehen zwar SQL-Schemas, allerdings tue ich mich etwas schwer damit das gut zu lesen.
Außerdem generiere ich die Doku der Datenbank direkt wenn ich Sie auch ändern müsste: Beim Update per Alembic oder was auch immer ihr bevorzugt.
Und so hätten wir ein Format das zum einen für alle beteiligten, von Claude über Gemini und GPT, bis mir selber gut lesbar ist und dann noch die Möglichkeit hat, das ich dort noch Meta Daten anhängen kann, in einer Art die SQL nicht hergibt.
Danach erhalte ich eine Datei pro Tabelle, die so aussieht:
---
type: database-table
title: user_roles
description: Zuordnungstabelle für Rollen. Enthält Auditing-Metadaten, welcher User
die Rolle vergeben hat.
okf: 1
table: user_roles
columns:
- name: user_id
type: uuid
nullable: false
primary_key: true
references: users.id
- name: role_id
type: uuid
nullable: false
primary_key: true
references: roles.id
- name: assigned_at
type: timestamp
nullable: true
- name: assigned_by_user_id
type: uuid
nullable: true
references: users.id
---
role_id 999 muss drin bleiben bis das Issue für Zuweisung von Gruppenrollen geschlossen wurde
Ich kann hier zeitlich begrenzt Metadaten anhängen ohne Ständig die Datenbank Kommentare zu ändern.
Das ganze wird in Git getracked und kann nach dem Review der das Issue schließt direkt entfernt werden.
Ich muss das Tool nicht wechseln um die Doku aktuell zu halten.
Aber du hast ja nur bei Google abgeschrieben
Ja, ich habe mal kurz rüber geluschert. Okay, nein nicht ganz, ich habe den Beitrag https://cloud.google.com/blog/products/data-analytics/how-the-open-knowledge-format-can-improve-data-sharing?hl=en erst gelesen als ich diesen Post hier verfasst habe und mein kleines PoC unter https://github.com/thorsti/erd2okf veröffentlicht habe.
Ja, Google hat auch Datenbanktabellen als Beispiel genommen. Aber das Schema steht dort im Body.
Ich habe das Schema bewusst ins Frontmatter gepackt: Der generierte Teil und der handgeschriebene Teil sind sauber getrennt. Die Struktur kann bei jeder Migration neu geschrieben werden, ohne dass meine Notizen im Body angefasst werden und der Drift-Check vergleicht YAML gegen die DB, statt Markdown-Tabellen aus Freitext zu parsen.
Googles Vorschlag ist es, das ein Agent Dateien pflegt. Mein Vorschlag ist es die Doku in der CI prüfbar zu machen und den Finger auf die Wunde zu legen: Hier stimmt was nicht.
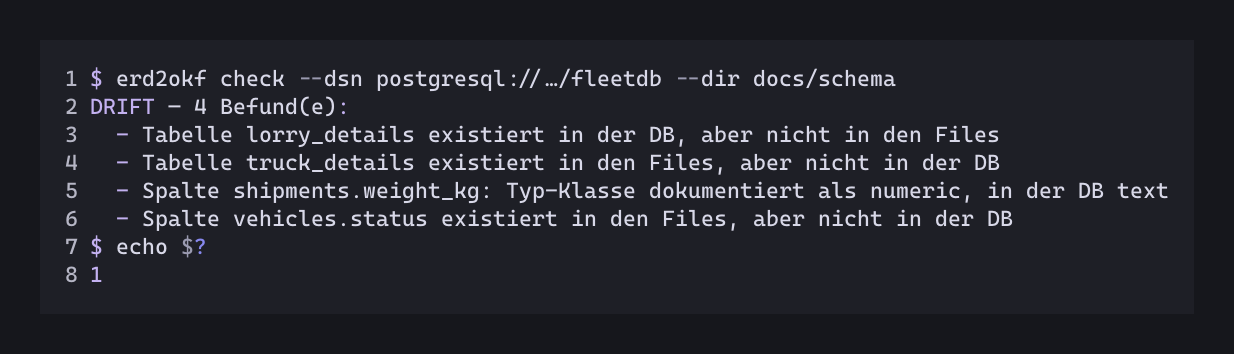
Ein Rename kann das Tool nicht von drop & add unterscheiden, muss es auch nicht, beides wird rot.